AWS AppSync Subscriptions: Detaching Prolonged Operations

💻 Full Stack Software Engineer and ☁ Serverless Developer, focused on building efficient and cost-effective applications using cloud-based technologies
TL;DR: This article discusses how to use AppSync Subscriptions to decouple long-running tasks from front-end requests in a serverless chat application. It provides a step-by-step guide to implement this solution, including an architecture overview, decoupling and processing steps, prerequisites, GraphQL schema, AppSync API configuration, DataSources and Resolvers, and Lambda function setup. The sample code and complete implementation can be found in the provided GitHub repository.
Introduction
When building APIs, developers often face the issue of long-running tasks timing out requests from the Front End or difficulty decoupling those longer tasks from the actual FE requests while informing it of the execution status.
In this article, and as part of the Serverless Holiday Hackathon, we will review how developers can take advantage of AppSync Subscriptions to decuple long-running tasks from the actual FE request.
Architecture Overview
The Hackathon challenges participants to build holiday-themed chat applications that use Generative AI.
While building such an application, developers will probably face the possible difficulties:
Requests to Badrock or any other LLM API could entice long-running requests to generate longer responses, these could take longer than 30 seconds and timeout the requests
Not knowing how to take advantage of streamed responses, which would provide the final user with a more interactive experience.
With this example, we will cover how to resolve both scenarios in two simple steps, while still leaving room for improvement and personalization.
Step 1: Decoupling
As the first step, we will need to decouple the front-end request from the actual processing. To do so, we can configure a JS Resolver to send the message to be processed to a SQS queue.
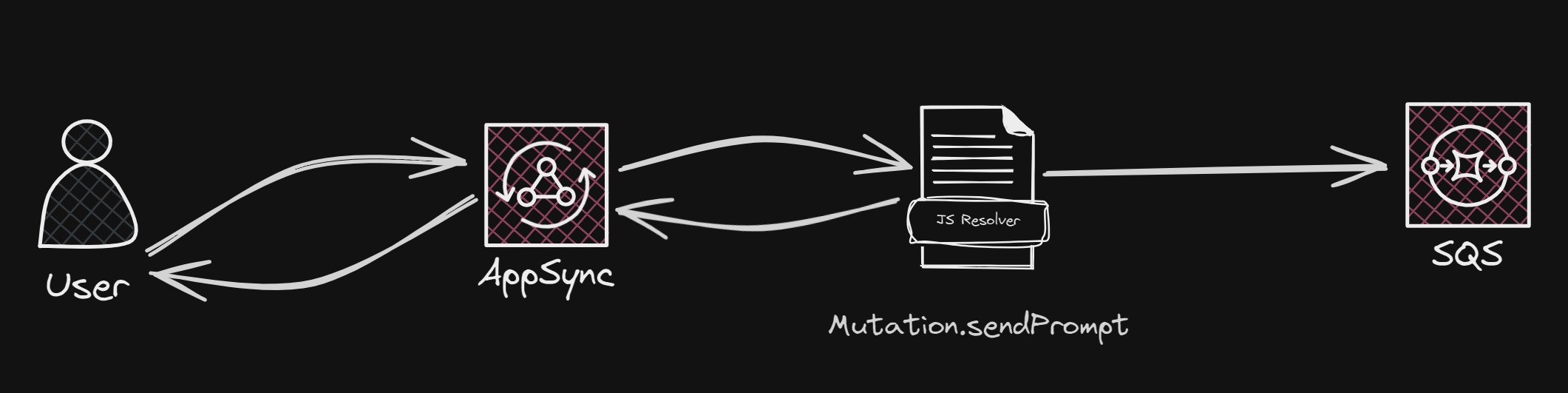
The flow would look like this:
The user sends a request to AppSync.
The JS Resolver creates a unique identifier for the received prompt and adds the message to the SQS Queue.
AppSync returns the unique identifiers to the User.
The User will need the response for the following step.
Step 2: Process and Notify
The second step will handle the prompt processing and notifying the user by sending a dummy mutation request that will trigger a subscription.
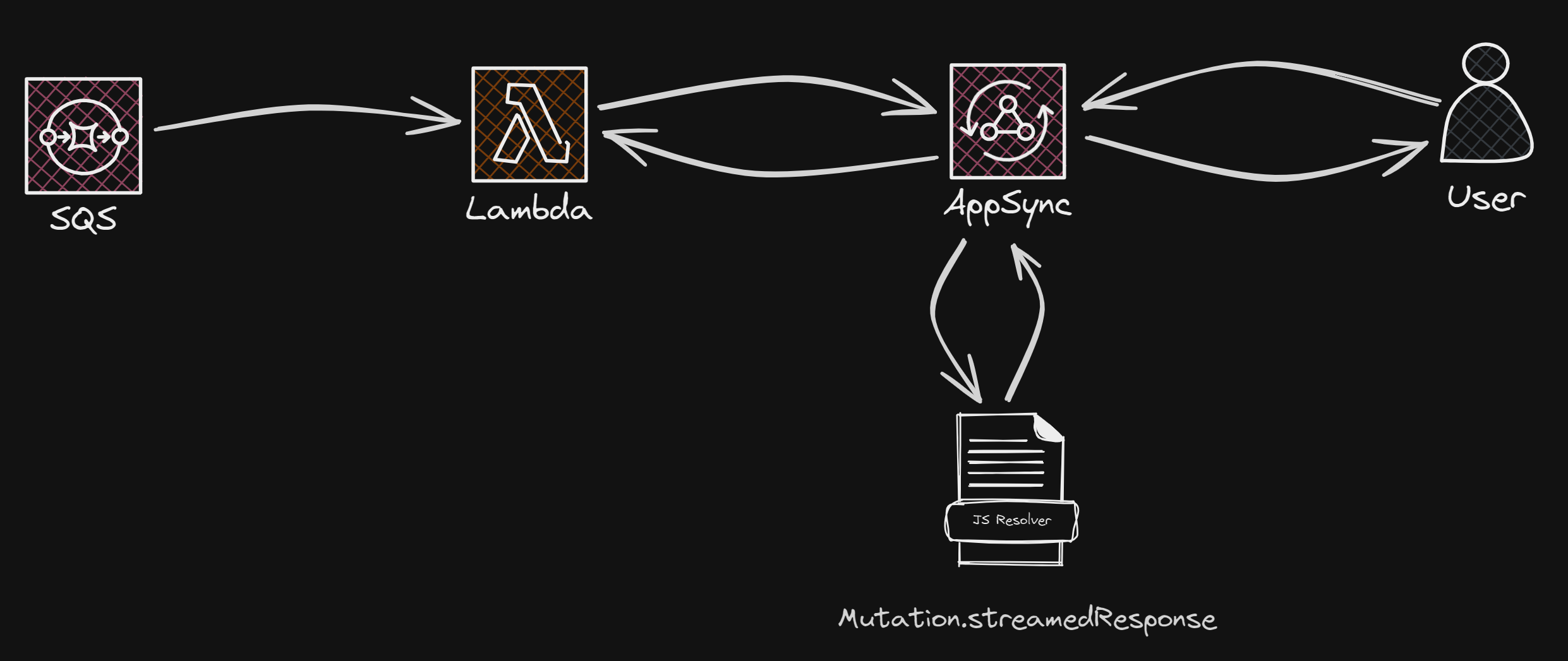
The flow for this step would be composed of the following steps:
The user subscribes via AppSync to updates on the
streamedResponsemutation using the provided identifiers in the previous response.The SQS Queue will trigger the Lambda for each message added to the same Queue by the above-explained mutation.
The Lambda Function will send a
streamedResponsemutation request for all updates that we want to notify the user with.Each request sent as a
streamedResponsemutation will trigger subscribed users to be notified by every response that matches the filtering requirements.
Implementing the solution
In this section, we will go over how to implement the solution that we described in the previous step.
All details and code can be found in the following sample application repository.
Prerequisites
To correctly follow and deploy the sample application, developers will need to fulfill the following requisites:
Node JS installation
AWS Account to deploy the API
Postman or GraphBolt to send requests and test the flow
GraphQL Schema
A mock schema has been defined for this application, part of the schema can be seen here:
schema {
query: Query
mutation: Mutation
subscription: Subscription
}
type Query @aws_api_key @aws_iam {
getSessionId: ID!
}
type Mutation {
sendPrompt(userPrompt: userPrompt!): promptResponse @aws_api_key @aws_iam
streamedResponse(streamedResponseInput: StreamedResponseInput!): StreamedResponse @aws_iam
}
type Subscription @aws_api_key @aws_iam {
onStreamedResponse(sessionId: ID!): StreamedResponse @aws_subscribe(mutations: ["streamedResponse"])
}
The most important part of it is the auth directives for the mutations, where streamedResponse is only enabled for @aws_iam.
This is an important configuration aspect as we want only our Back End services to be able to trigger this mutation.
AppSync API
To configure the AppSync API using Serverless Framework we will be taking advantage of the Serverless AppSync Plugin.
appSync:
name: ${self:custom.base}-appsync
logging:
level: ALL
retentionInDays: 1
xrayEnabled: true
authentication:
type: AWS_IAM
additionalAuthentications:
- type: API_KEY
apiKeys:
- ${self:custom.base}-key
substitutions:
accountId:
Ref: AWS::AccountId
queueName: decoupling-sqs
...
Some key insights from the above configuration:
Cloudwatch can end up being expensive, but to avoid racking up a high bill we configured them to only be retained for one day. We kept the log level to
ALLto ensure we can see all logs during debugging, but make sure to lower that for any production projects, AppSync Logs are very verbose.Multiple authentication methods, we want two different auth methods to ensure that: Our API is private and that we can limit who can trigger the
streamedResponsemutation.Substitutions: AppSync resolvers don't support environment variables, a workaround for that would be to use substitutions. This feature will act as environment variables by substituting some mock text in the resolver code with the actual required values.
DataSources and Resolvers
Apart from the above API configuration we also need to ensure we configure the code that will resolve each operation and the different data sources used by them.
...
dataSources:
localResolverDS:
type: "NONE"
sqsDS:
type: "HTTP"
config:
endpoint: !Sub https://sqs.${AWS::Region}.amazonaws.com/
iamRoleStatements:
- Effect: "Allow"
Action:
- "sqs:*"
Resource:
Fn::GetAtt:
- MyQueue
- Arn
authorizationConfig:
authorizationType: AWS_IAM
awsIamConfig:
signingRegion:
Ref: AWS::Region
signingServiceName: sqs
resolvers:
Mutation.sendPrompt:
kind: UNIT
dataSource: sqsDS
code: "./src/appsync/sendPrompt.js"
Mutation.streamedResponse:
kind: UNIT
dataSource: localResolverDS
code: "./src/appsync/streamedResponse.js"
Key takeaways from this config are:
Data Sources: What Resolvers use to fetch data and resolve operations. In this case, we configure two different types.
NONE: Used for resolvers that only rely on local business logic, without the need to retrieve/send any informationHTTP: Not all AWS services are supported to integrate directly with AppSync, but if it has an HTTP endpoint, you can trigger it via HTTP request. For example, SQS.
Resolvers: In this section, we define what kind, data source and code will be used to resolve a specific operation or data type.
Decoupling Lambda
Once we have the API up and running, we can focus on how to configure a Lambda function to process all messages from the SQS Queue.
functions:
sqsHandler:
handler: src/decoupled.handler
role: LambdaRole
logRetentionInDays: 1
environment:
GRAPHQL_ENDPOINT: { Fn::GetAtt: [GraphQlApi, GraphQLUrl] }
REGION:
Ref: AWS::Region
events:
- sqs:
arn:
Fn::GetAtt:
- MyQueue
- Arn
batchSize: 1
This configuration is not different than any other Lambda Function triggered by a SQS Queue. But there are still some takeaway points from this configuration:
IAM Role: Developers will need to add and configure a custom IAM role for this Lambda role to be able to sign requests to AppSync.
Log retention: Similar to the AppSync configuration, we want to limit the time that the logs are stored, in this case, the logs should be deleted after one day.
AppSync API Endpoint: Something that developers can struggle with is getting the URL endpoint from the AppSync API generated in the same
serverless.yml. To get that value one could use{ Fn::GetAtt: [GraphQlApi, GraphQLUrl] }to resolve it during deployment.
Implementing the code
The code to complete the above example configuration can be found on the provided Github Repository, but the following is an example of one of the trickiest parts.
import { util } from "@aws-appsync/utils";
const accountId = "#accountId#";
const queueName = "#queueName#";
export function request(ctx) {
const { userPrompt } = ctx.args;
const msgBody = {
...userPrompt,
messageId: util.autoId(),
};
ctx.stash.msgBody = msgBody;
return {
version: "2018-05-29",
method: "POST",
resourcePath: `/${accountId}/${queueName}`,
params: {
body: `Action=SendMessage&Version=2012-11-05&MessageBody=${JSON.stringify(
msgBody
)}`,
headers: {
"content-type": "application/x-www-form-urlencoded",
},
},
};
}
The code sample is part of the JS resolver configured for the sendPrompt mutation. As part of this sample, we can learn:
JS Resolver substitutions: When using substitutions with JS resolvers, developers need to make sure they define a variable
const accountId = "#accountId#";where the value will be replaced with the value provided in the configuration with the same name as the one between the#.Building a
HTTPrequest: The returned object by therequestfunction is an example of how to build an HTTP request for accessing/triggering the SQS API.
Conclusions
In conclusion, AWS AppSync Subscriptions can effectively decouple long-running tasks from front-end requests in serverless chat applications.
By implementing the two-step process of decoupling and processing with notifications, developers can enhance user experience and avoid request timeouts.
The provided sample code and repository offer a practical guide to implementing this solution, showcasing the use of GraphQL schema, AppSync API configuration, data sources, resolvers, and Lambda function setup.
References
Sample Github Repository: https://github.com/Lorenzohidalgo/appsync-decoupling-sample
Serverless AppSync Repository: https://github.com/sid88in/serverless-appsync-plugin
![[Video] DynamoDB for Relational People - AWS Community Day Turkiye 2025](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1759391824928%2Ff05a85d0-5353-4abb-bef6-3ef66e2f094f.jpeg&w=3840&q=75)


![[Webinar] DynamoDB - Common mistakes and how to optimize usage](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1722499330481%2F58678e4e-d77e-4acf-b76f-4c142504782b.png&w=3840&q=75)